TensorFlow’s tf.data.service with Amazon SageMaker Training Heterogeneous Clusters
Introduction
Heterogeneous clusters enable launching training jobs that use multiple instance types in a single job. This capability can improve your training cost and speed by running different parts of the model training on the most suitable instance type. This use case typically happens in computer vision (CV) deep learning (DL) training, where training is bottleneck on CPU resources needed for data augmentation, leaving the expensive GPU underutilized. Heterogeneous clusters enable you to add more CPU resources to fully utilize GPUs to increase training speed and cost-efficiency. For more details, you can find the documentation of this feature here.
This notebook demonstrates how to use Heterogeneous Clusters with TensorFlow’s tf.data.service. It includes training a CPU intensive DL CV workload. Comparing cost and performance between homogeneous and heterogeneous training configurations.
💡To get started quickly with heterogeneous clusters, we suggest you’ll reuse the provided code as a quick way to migrate your workload from a local tf.data pipeline to a distributed tf.data.service pipeline. You’ll need to change code/train_dnn.py, while keeping code/train_data.py and code/launcher.py intact. This is explained below in the [Workload Details] section.
This notebook covers: - A guide to switching from a homogeneous job (single instance type) to a heterogeneous job (multiple instance types) - Explaining to use Heterogeneous clusters with TensorFlow’s tf.data.service - Set up Amazon SageMaker Studio Notebook - Run homogeneous cluster training job - Run heterogeneous cluster training job - Compare time and cost to train between homogeneous and heterogeneous clusters - Conclusion
A guide to switching from a homogeneous to a heterogeneous job
This notebook runs and compares these two workloads:
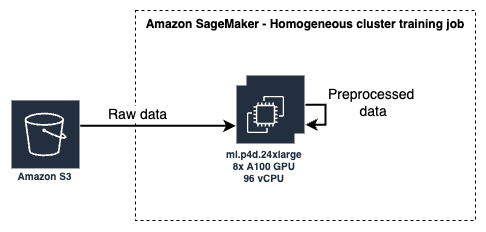
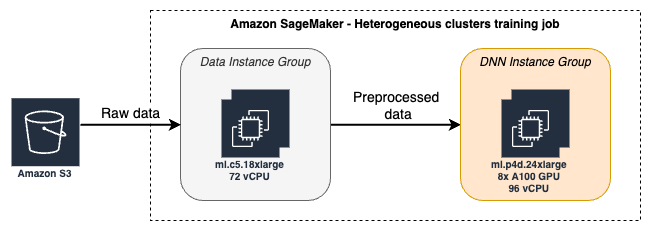
The heterogeneous job will include two instance groups: - data_group - A group of CPU instances that will run data pre-processing code. - dnn_group - A group of GPU instances that will run Deep Neural Network training code.
In this example, the inter-node communication between CPU and GPU instance groups is implemented using TensorFlow data service feature. This feature allows offloading a configurable amount of preprocessing work to worker machines. Note that SageMaker’s Heterogeneous cluster does not provide out-of-the-box support for inter-instance_group communication, and it is up to the user to implement (we provide reference implementation here).
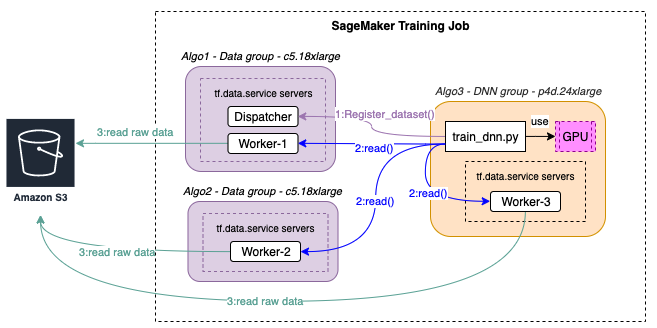
launcher.py is responsible for detecting the instance group the instance belong to, and start train_dnn.py and train_data.py accordingly. It is also responsible for shutting down tf.data.services the training script
completes (train_dnn.py) so all instances exit allowing the SageMaker training job to complete. In every instance luncher.py will use train_data.py to start a tf.data.service worker server (As all instance types have CPUs that could be used for preprocessing). luncher.py will start a single tf.data.service dispatcher server (on the first instance of the data_group).luncher.py will start the train_dnn.py script in all GPU instances (dnn_group instances).Learn more about tf.data.service processes
tf.data.service Dispatcher - The dispatcher server acts as the control plain for tf.data.service; Being responsible for registering worker servers and assigning preprocessing tasks to them. Each training job has a single Dispatcher running in the first instance of the data_group and listens on port 6000. tf.data.service Workers - Worker servers carry out the data processing. Each instance could have one or more workers (listen on port 6001/6002/…).
Defining what part of your pipeline runs in which instance group
When you apply tf.data.experimental.service.distribute() on your dataset, all preprocessing operations defined up to the apply will run on the tf.data.service workers, and all dataset operations defined afterwords will run on the local process. All instances will need access to a dataset you’ll make available through a SageMaker training data channel. You do have the option of limiting which instance group will see which training data channel.
The below figure shows sequence of events of setting up and running in a tf.data.service based heterogeneous cluster training job.
security groups update if running in private VPC
subnets and security_group_ids parameters when defining an Estimator).A. Set up SageMaker Studio notebook
Before you start
Ensure you have selected Python 3 (TensorFlow 2.6 Python 3.8 CPU Optimized) image for your SageMaker Studio Notebook instance, and running on ml.t3.medium instance type.
Step 1 - Upgrade SageMaker SDK and dependent packages
Heterogeneous Clusters for Amazon SageMaker model training was announced on 07/08/2022. This feature release requires you to have updated SageMaker SDK, Boto3 client.
[3]:
%%bash
python3 -m pip install --upgrade boto3 botocore awscli sagemaker
Requirement already satisfied: boto3 in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages (1.24.72)
Collecting boto3
Downloading boto3-1.24.80-py3-none-any.whl (132 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 132.5/132.5 kB 925.9 kB/s eta 0:00:00
Requirement already satisfied: botocore in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages (1.27.72)
Collecting botocore
Downloading botocore-1.27.80-py3-none-any.whl (9.1 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 9.1/9.1 MB 16.4 MB/s eta 0:00:00
Requirement already satisfied: awscli in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages (1.25.73)
Collecting awscli
Downloading awscli-1.25.81-py3-none-any.whl (3.9 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 3.9/3.9 MB 38.4 MB/s eta 0:00:00
Requirement already satisfied: sagemaker in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages (2.109.0)
Requirement already satisfied: s3transfer<0.7.0,>=0.6.0 in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages (from boto3) (0.6.0)
Requirement already satisfied: jmespath<2.0.0,>=0.7.1 in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages/jmespath-1.0.0-py3.9.egg (from boto3) (1.0.0)
Requirement already satisfied: urllib3<1.27,>=1.25.4 in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages/urllib3-1.26.9-py3.9.egg (from botocore) (1.26.9)
Requirement already satisfied: python-dateutil<3.0.0,>=2.1 in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages/python_dateutil-2.8.2-py3.9.egg (from botocore) (2.8.2)
Requirement already satisfied: PyYAML<5.5,>=3.10 in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages (from awscli) (5.4.1)
Requirement already satisfied: docutils<0.17,>=0.10 in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages (from awscli) (0.16)
Requirement already satisfied: colorama<0.4.5,>=0.2.5 in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages (from awscli) (0.4.4)
Requirement already satisfied: rsa<4.8,>=3.1.2 in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages (from awscli) (4.7.2)
Requirement already satisfied: importlib-metadata<5.0,>=1.4.0 in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages/importlib_metadata-4.11.3-py3.9.egg (from sagemaker) (4.11.3)
Requirement already satisfied: pathos in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages/pathos-0.2.8-py3.9.egg (from sagemaker) (0.2.8)
Requirement already satisfied: protobuf3-to-dict<1.0,>=0.1.5 in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages/protobuf3_to_dict-0.1.5-py3.9.egg (from sagemaker) (0.1.5)
Requirement already satisfied: pandas in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages/pandas-1.4.2-py3.9-macosx-10.9-x86_64.egg (from sagemaker) (1.4.2)
Requirement already satisfied: numpy<2.0,>=1.9.0 in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages (from sagemaker) (1.22.4)
Requirement already satisfied: attrs<22,>=20.3.0 in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages/attrs-20.3.0-py3.9.egg (from sagemaker) (20.3.0)
Requirement already satisfied: smdebug-rulesconfig==1.0.1 in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages/smdebug_rulesconfig-1.0.1-py3.9.egg (from sagemaker) (1.0.1)
Requirement already satisfied: google-pasta in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages/google_pasta-0.2.0-py3.9.egg (from sagemaker) (0.2.0)
Requirement already satisfied: protobuf<4.0,>=3.1 in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages (from sagemaker) (3.20.1)
Requirement already satisfied: packaging>=20.0 in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages/packaging-21.3-py3.9.egg (from sagemaker) (21.3)
Requirement already satisfied: zipp>=0.5 in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages/zipp-3.7.0-py3.9.egg (from importlib-metadata<5.0,>=1.4.0->sagemaker) (3.7.0)
Requirement already satisfied: pyparsing!=3.0.5,>=2.0.2 in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages/pyparsing-3.0.7-py3.9.egg (from packaging>=20.0->sagemaker) (3.0.7)
Requirement already satisfied: six in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages (from protobuf3-to-dict<1.0,>=0.1.5->sagemaker) (1.15.0)
Requirement already satisfied: pyasn1>=0.1.3 in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages (from rsa<4.8,>=3.1.2->awscli) (0.4.8)
Requirement already satisfied: pytz>=2020.1 in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages/pytz-2022.1-py3.9.egg (from pandas->sagemaker) (2022.1)
Requirement already satisfied: dill>=0.3.4 in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages/dill-0.3.4-py3.9.egg (from pathos->sagemaker) (0.3.4)
Requirement already satisfied: multiprocess>=0.70.12 in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages/multiprocess-0.70.12.2-py3.9.egg (from pathos->sagemaker) (0.70.12.2)
Requirement already satisfied: pox>=0.3.0 in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages/pox-0.3.0-py3.9.egg (from pathos->sagemaker) (0.3.0)
Requirement already satisfied: ppft>=1.6.6.4 in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages/ppft-1.6.6.4-py3.9.egg (from pathos->sagemaker) (1.6.6.4)
Installing collected packages: botocore, boto3, awscli
Attempting uninstall: botocore
Found existing installation: botocore 1.27.72
Uninstalling botocore-1.27.72:
Successfully uninstalled botocore-1.27.72
Attempting uninstall: boto3
Found existing installation: boto3 1.24.72
Uninstalling boto3-1.24.72:
Successfully uninstalled boto3-1.24.72
Attempting uninstall: awscli
Found existing installation: awscli 1.25.73
Uninstalling awscli-1.25.73:
Successfully uninstalled awscli-1.25.73
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
sagemaker-training 4.2.2 requires protobuf<3.20,>=3.9.2, but you have protobuf 3.20.1 which is incompatible.
Successfully installed awscli-1.25.81 boto3-1.24.80 botocore-1.27.80
Step 2 - Restart the notebook kernel
[ ]:
#import IPython
#IPython.Application.instance().kernel.do_shutdown(True)
Step 3 - Validate SageMaker Python SDK and TensorFlow versions
Ensure the output of the cell below reflects:
SageMaker Python SDK version 2.98.0 or above,
boto3 1.24 or above
botocore 1.27 or above
TensorFlow 2.6 or above
[4]:
!pip show sagemaker boto3 botocore tensorflow protobuf |egrep 'Name|Version|---'
Name: sagemaker
Version: 2.109.0
---
Name: boto3
Version: 1.24.80
---
Name: botocore
Version: 1.27.80
---
Name: tensorflow
Version: 2.8.0
---
Name: protobuf
Version: 3.20.1
[5]:
import os
import json
import datetime
import sagemaker
from sagemaker import get_execution_role
from sagemaker.instance_group import InstanceGroup
sess = sagemaker.Session()
role = get_execution_role()
C. Run a homogeneous training job
Step 1: Set up the training environment
In this step, we define and submit a homogeneous training job. It uses a single instance type (p4d.24xlarge) with 8 GPUs. The analysis of the job will shows that it is CPU bound and therefore its GPUs are underutilized.
[6]:
import datetime
from sagemaker.tensorflow import TensorFlow
from sagemaker.instance_group import InstanceGroup
import os
hyperparameters = {
"epochs": 10,
"steps_per_epoch": 500,
"batch_size": 1024,
"tf_data_mode": "local", # We won't be using tf.data.service ('service') for this homogeneous job
"num_of_data_workers": 0, # We won't be using tf.data.service ('service') for this homogeneous job
}
estimator = TensorFlow(
entry_point="launcher.py",
source_dir="code",
framework_version="2.9.1",
py_version="py39",
role=role,
volume_size=10,
max_run=1800, # 30 minutes
disable_profiler=True,
instance_type="ml.p4d.24xlarge",
instance_count=1,
hyperparameters=hyperparameters,
distribution={
"mpi": {
"enabled": True,
"processes_per_host": 8, # 8 GPUs per host
"custom_mpi_options": "--NCCL_DEBUG WARN",
},
},
)
Step 2: Submit the training job
Note: For the logs, click on View logs from the Training Jobs node in Amazon SageMaker Console.
[17]:
from start_job_utils import fit_with_retries
fit_with_retries(5, estimator,
job_name="homogeneous-" + datetime.datetime.utcnow().strftime("%Y%m%dT%H%M%SZ"),
)
2022-09-24 11:28:23 Starting - Starting the training job......
2022-09-24 11:29:08 Starting - Preparing the instances for training........................
2022-09-24 11:33:34 Downloading - Downloading input data
2022-09-24 11:33:34 Training - Downloading the training image..................
2022-09-24 11:37:00 Training - Training image download completed. Training in progress..2022-09-24 11:37:05.792579: W tensorflow/core/profiler/internal/smprofiler_timeline.cc:460] Initializing the SageMaker Profiler.
2022-09-24 11:37:05.801314: W tensorflow/core/profiler/internal/smprofiler_timeline.cc:105] SageMaker Profiler is not enabled. The timeline writer thread will not be started, future recorded events will be dropped.
2022-09-24 11:37:06.269740: W tensorflow/core/profiler/internal/smprofiler_timeline.cc:460] Initializing the SageMaker Profiler.
2022-09-24 11:37:13,412 sagemaker-training-toolkit INFO Imported framework sagemaker_tensorflow_container.training
2022-09-24 11:37:14,075 sagemaker-training-toolkit INFO Installing dependencies from requirements.txt:
/usr/local/bin/python3.9 -m pip install -r requirements.txt
Collecting protobuf==3.20.1
Downloading protobuf-3.20.1-cp39-cp39-manylinux_2_5_x86_64.manylinux1_x86_64.whl (1.0 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 1.0/1.0 MB 39.6 MB/s eta 0:00:00
Collecting tensorflow-addons==0.17.0
Downloading tensorflow_addons-0.17.0-cp39-cp39-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (1.1 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 1.1/1.1 MB 51.6 MB/s eta 0:00:00
Requirement already satisfied: packaging in /usr/local/lib/python3.9/site-packages (from tensorflow-addons==0.17.0->-r requirements.txt (line 2)) (21.3)
Requirement already satisfied: typeguard>=2.7 in /usr/local/lib/python3.9/site-packages (from tensorflow-addons==0.17.0->-r requirements.txt (line 2)) (2.13.3)
Requirement already satisfied: pyparsing!=3.0.5,>=2.0.2 in /usr/local/lib/python3.9/site-packages (from packaging->tensorflow-addons==0.17.0->-r requirements.txt (line 2)) (3.0.9)
Installing collected packages: protobuf, tensorflow-addons
Attempting uninstall: protobuf
Found existing installation: protobuf 3.19.4
Uninstalling protobuf-3.19.4:
Successfully uninstalled protobuf-3.19.4
Attempting uninstall: tensorflow-addons
Found existing installation: tensorflow-addons 0.17.1
Uninstalling tensorflow-addons-0.17.1:
Successfully uninstalled tensorflow-addons-0.17.1
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
tf-models-official 2.9.1 requires tensorflow~=2.9.0, which is not installed.
tensorflow-gpu 2.9.1 requires protobuf<3.20,>=3.9.2, but you have protobuf 3.20.1 which is incompatible.
tensorboard 2.9.1 requires protobuf<3.20,>=3.9.2, but you have protobuf 3.20.1 which is incompatible.
sagemaker-training 4.1.4.dev0 requires protobuf<3.20,>=3.9.2, but you have protobuf 3.20.1 which is incompatible.
Successfully installed protobuf-3.20.1 tensorflow-addons-0.17.0
WARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv
[notice] A new release of pip available: 22.1.2 -> 22.2.2
[notice] To update, run: pip install --upgrade pip
2022-09-24 11:37:24,079 sagemaker-training-toolkit INFO Waiting for the process to finish and give a return code.
2022-09-24 11:37:24,079 sagemaker-training-toolkit INFO Done waiting for a return code. Received 0 from exiting process.
2022-09-24 11:37:24,258 sagemaker-training-toolkit INFO Starting MPI run as worker node.
2022-09-24 11:37:24,258 sagemaker-training-toolkit INFO Creating SSH daemon.
2022-09-24 11:37:24,274 sagemaker-training-toolkit INFO Waiting for MPI workers to establish their SSH connections
2022-09-24 11:37:24,274 sagemaker-training-toolkit INFO Env Hosts: ['algo-1'] Hosts: ['algo-1:8'] process_per_hosts: 8 num_processes: 8
2022-09-24 11:37:24,276 sagemaker-training-toolkit INFO Network interface name: eth0
2022-09-24 11:37:24,368 sagemaker-training-toolkit INFO Invoking user script
Training Env:
{
"additional_framework_parameters": {
"sagemaker_mpi_custom_mpi_options": "--NCCL_DEBUG WARN",
"sagemaker_mpi_enabled": true,
"sagemaker_mpi_num_of_processes_per_host": 8
},
"channel_input_dirs": {},
"current_host": "algo-1",
"current_instance_group": "homogeneousCluster",
"current_instance_group_hosts": [
"algo-1"
],
"current_instance_type": "ml.p4d.24xlarge",
"distribution_hosts": [
"algo-1"
],
"distribution_instance_groups": [
"homogeneousCluster"
],
"framework_module": "sagemaker_tensorflow_container.training:main",
"hosts": [
"algo-1"
],
"hyperparameters": {
"batch_size": 1024,
"epochs": 10,
"model_dir": "/opt/ml/model",
"num_of_data_workers": 0,
"steps_per_epoch": 500,
"tf_data_mode": "local"
},
"input_config_dir": "/opt/ml/input/config",
"input_data_config": {},
"input_dir": "/opt/ml/input",
"instance_groups": [
"homogeneousCluster"
],
"instance_groups_dict": {
"homogeneousCluster": {
"instance_group_name": "homogeneousCluster",
"instance_type": "ml.p4d.24xlarge",
"hosts": [
"algo-1"
]
}
},
"is_hetero": false,
"is_master": true,
"job_name": "homogeneous-20220924T112821Z-1",
"log_level": 20,
"master_hostname": "algo-1",
"model_dir": "/opt/ml/model",
"module_dir": "s3://sagemaker-us-east-1-331113010199/homogeneous-20220924T112821Z-1/source/sourcedir.tar.gz",
"module_name": "launcher",
"network_interface_name": "eth0",
"num_cpus": 96,
"num_gpus": 8,
"output_data_dir": "/opt/ml/output/data",
"output_dir": "/opt/ml/output",
"output_intermediate_dir": "/opt/ml/output/intermediate",
"resource_config": {
"current_host": "algo-1",
"current_instance_type": "ml.p4d.24xlarge",
"current_group_name": "homogeneousCluster",
"hosts": [
"algo-1"
],
"instance_groups": [
{
"instance_group_name": "homogeneousCluster",
"instance_type": "ml.p4d.24xlarge",
"hosts": [
"algo-1"
]
}
],
"network_interface_name": "eth0"
},
"user_entry_point": "launcher.py"
}
Environment variables:
SM_HOSTS=["algo-1"]
SM_NETWORK_INTERFACE_NAME=eth0
SM_HPS={"batch_size":1024,"epochs":10,"model_dir":"/opt/ml/model","num_of_data_workers":0,"steps_per_epoch":500,"tf_data_mode":"local"}
SM_USER_ENTRY_POINT=launcher.py
SM_FRAMEWORK_PARAMS={"sagemaker_mpi_custom_mpi_options":"--NCCL_DEBUG WARN","sagemaker_mpi_enabled":true,"sagemaker_mpi_num_of_processes_per_host":8}
SM_RESOURCE_CONFIG={"current_group_name":"homogeneousCluster","current_host":"algo-1","current_instance_type":"ml.p4d.24xlarge","hosts":["algo-1"],"instance_groups":[{"hosts":["algo-1"],"instance_group_name":"homogeneousCluster","instance_type":"ml.p4d.24xlarge"}],"network_interface_name":"eth0"}
SM_INPUT_DATA_CONFIG={}
SM_OUTPUT_DATA_DIR=/opt/ml/output/data
SM_CHANNELS=[]
SM_CURRENT_HOST=algo-1
SM_CURRENT_INSTANCE_TYPE=ml.p4d.24xlarge
SM_CURRENT_INSTANCE_GROUP=homogeneousCluster
SM_CURRENT_INSTANCE_GROUP_HOSTS=["algo-1"]
SM_INSTANCE_GROUPS=["homogeneousCluster"]
SM_INSTANCE_GROUPS_DICT={"homogeneousCluster":{"hosts":["algo-1"],"instance_group_name":"homogeneousCluster","instance_type":"ml.p4d.24xlarge"}}
SM_DISTRIBUTION_INSTANCE_GROUPS=["homogeneousCluster"]
SM_IS_HETERO=false
SM_MODULE_NAME=launcher
SM_LOG_LEVEL=20
SM_FRAMEWORK_MODULE=sagemaker_tensorflow_container.training:main
SM_INPUT_DIR=/opt/ml/input
SM_INPUT_CONFIG_DIR=/opt/ml/input/config
SM_OUTPUT_DIR=/opt/ml/output
SM_NUM_CPUS=96
SM_NUM_GPUS=8
SM_MODEL_DIR=/opt/ml/model
SM_MODULE_DIR=s3://sagemaker-us-east-1-331113010199/homogeneous-20220924T112821Z-1/source/sourcedir.tar.gz
SM_TRAINING_ENV={"additional_framework_parameters":{"sagemaker_mpi_custom_mpi_options":"--NCCL_DEBUG WARN","sagemaker_mpi_enabled":true,"sagemaker_mpi_num_of_processes_per_host":8},"channel_input_dirs":{},"current_host":"algo-1","current_instance_group":"homogeneousCluster","current_instance_group_hosts":["algo-1"],"current_instance_type":"ml.p4d.24xlarge","distribution_hosts":["algo-1"],"distribution_instance_groups":["homogeneousCluster"],"framework_module":"sagemaker_tensorflow_container.training:main","hosts":["algo-1"],"hyperparameters":{"batch_size":1024,"epochs":10,"model_dir":"/opt/ml/model","num_of_data_workers":0,"steps_per_epoch":500,"tf_data_mode":"local"},"input_config_dir":"/opt/ml/input/config","input_data_config":{},"input_dir":"/opt/ml/input","instance_groups":["homogeneousCluster"],"instance_groups_dict":{"homogeneousCluster":{"hosts":["algo-1"],"instance_group_name":"homogeneousCluster","instance_type":"ml.p4d.24xlarge"}},"is_hetero":false,"is_master":true,"job_name":"homogeneous-20220924T112821Z-1","log_level":20,"master_hostname":"algo-1","model_dir":"/opt/ml/model","module_dir":"s3://sagemaker-us-east-1-331113010199/homogeneous-20220924T112821Z-1/source/sourcedir.tar.gz","module_name":"launcher","network_interface_name":"eth0","num_cpus":96,"num_gpus":8,"output_data_dir":"/opt/ml/output/data","output_dir":"/opt/ml/output","output_intermediate_dir":"/opt/ml/output/intermediate","resource_config":{"current_group_name":"homogeneousCluster","current_host":"algo-1","current_instance_type":"ml.p4d.24xlarge","hosts":["algo-1"],"instance_groups":[{"hosts":["algo-1"],"instance_group_name":"homogeneousCluster","instance_type":"ml.p4d.24xlarge"}],"network_interface_name":"eth0"},"user_entry_point":"launcher.py"}
SM_USER_ARGS=["--batch_size","1024","--epochs","10","--model_dir","/opt/ml/model","--num_of_data_workers","0","--steps_per_epoch","500","--tf_data_mode","local"]
SM_OUTPUT_INTERMEDIATE_DIR=/opt/ml/output/intermediate
SM_HP_BATCH_SIZE=1024
SM_HP_EPOCHS=10
SM_HP_MODEL_DIR=/opt/ml/model
SM_HP_NUM_OF_DATA_WORKERS=0
SM_HP_STEPS_PER_EPOCH=500
SM_HP_TF_DATA_MODE=local
PYTHONPATH=/opt/ml/code:/usr/local/bin:/usr/local/lib/python39.zip:/usr/local/lib/python3.9:/usr/local/lib/python3.9/lib-dynload:/usr/local/lib/python3.9/site-packages:/usr/local/lib/python3.9/site-packages/smdebug-1.0.17b20220701-py3.9.egg:/usr/local/lib/python3.9/site-packages/pyinstrument-3.4.2-py3.9.egg:/usr/local/lib/python3.9/site-packages/pyinstrument_cext-0.2.4-py3.9-linux-x86_64.egg
Invoking script with the following command:
mpirun --host algo-1:8 -np 8 --allow-run-as-root --display-map --tag-output -mca btl_tcp_if_include eth0 -mca oob_tcp_if_include eth0 -mca plm_rsh_no_tree_spawn 1 -bind-to none -map-by slot -mca pml ob1 -mca btl ^openib -mca orte_abort_on_non_zero_status 1 -mca btl_vader_single_copy_mechanism none -x NCCL_MIN_NRINGS=4 -x NCCL_SOCKET_IFNAME=eth0 -x NCCL_DEBUG=WARN -x LD_LIBRARY_PATH -x PATH -x LD_PRELOAD=/usr/local/lib/python3.9/site-packages/gethostname.cpython-39-x86_64-linux-gnu.so -x SM_HOSTS -x SM_NETWORK_INTERFACE_NAME -x SM_HPS -x SM_USER_ENTRY_POINT -x SM_FRAMEWORK_PARAMS -x SM_RESOURCE_CONFIG -x SM_INPUT_DATA_CONFIG -x SM_OUTPUT_DATA_DIR -x SM_CHANNELS -x SM_CURRENT_HOST -x SM_CURRENT_INSTANCE_TYPE -x SM_CURRENT_INSTANCE_GROUP -x SM_CURRENT_INSTANCE_GROUP_HOSTS -x SM_INSTANCE_GROUPS -x SM_INSTANCE_GROUPS_DICT -x SM_DISTRIBUTION_INSTANCE_GROUPS -x SM_IS_HETERO -x SM_MODULE_NAME -x SM_LOG_LEVEL -x SM_FRAMEWORK_MODULE -x SM_INPUT_DIR -x SM_INPUT_CONFIG_DIR -x SM_OUTPUT_DIR -x SM_NUM_CPUS -x SM_NUM_GPUS -x SM_MODEL_DIR -x SM_MODULE_DIR -x SM_TRAINING_ENV -x SM_USER_ARGS -x SM_OUTPUT_INTERMEDIATE_DIR -x SM_HP_BATCH_SIZE -x SM_HP_EPOCHS -x SM_HP_MODEL_DIR -x SM_HP_NUM_OF_DATA_WORKERS -x SM_HP_STEPS_PER_EPOCH -x SM_HP_TF_DATA_MODE -x PYTHONPATH /usr/local/bin/python3.9 -m mpi4py launcher.py --batch_size 1024 --epochs 10 --model_dir /opt/ml/model --num_of_data_workers 0 --steps_per_epoch 500 --tf_data_mode local
Data for JOB [7555,1] offset 0 Total slots allocated 8
======================== JOB MAP ========================
Data for node: ip-10-0-215-180#011Num slots: 8#011Max slots: 0#011Num procs: 8
#011Process OMPI jobid: [7555,1] App: 0 Process rank: 0 Bound: N/A
#011Process OMPI jobid: [7555,1] App: 0 Process rank: 1 Bound: N/A
#011Process OMPI jobid: [7555,1] App: 0 Process rank: 2 Bound: N/A
#011Process OMPI jobid: [7555,1] App: 0 Process rank: 3 Bound: N/A
#011Process OMPI jobid: [7555,1] App: 0 Process rank: 4 Bound: N/A
#011Process OMPI jobid: [7555,1] App: 0 Process rank: 5 Bound: N/A
#011Process OMPI jobid: [7555,1] App: 0 Process rank: 6 Bound: N/A
#011Process OMPI jobid: [7555,1] App: 0 Process rank: 7 Bound: N/A
=============================================================
[1,mpirank:1,algo-1]<stdout>:env.is_hetero=False
[1,mpirank:1,algo-1]<stdout>:current_host=algo-1
[1,mpirank:1,algo-1]<stdout>:Opening process: ['python', './train_dnn.py', '--batch_size', '1024', '--epochs', '10', '--model_dir', '/opt/ml/model', '--num_of_data_workers', '0', '--steps_per_epoch', '500', '--tf_data_mode', 'local']
[1,mpirank:4,algo-1]<stdout>:env.is_hetero=False
[1,mpirank:4,algo-1]<stdout>:current_host=algo-1
[1,mpirank:4,algo-1]<stdout>:Opening process: ['python', './train_dnn.py', '--batch_size', '1024', '--epochs', '10', '--model_dir', '/opt/ml/model', '--num_of_data_workers', '0', '--steps_per_epoch', '500', '--tf_data_mode', 'local']
[1,mpirank:5,algo-1]<stdout>:env.is_hetero=False
[1,mpirank:5,algo-1]<stdout>:current_host=algo-1
[1,mpirank:5,algo-1]<stdout>:Opening process: ['python', './train_dnn.py', '--batch_size', '1024', '--epochs', '10', '--model_dir', '/opt/ml/model', '--num_of_data_workers', '0', '--steps_per_epoch', '500', '--tf_data_mode', 'local']
[1,mpirank:7,algo-1]<stdout>:env.is_hetero=False
[1,mpirank:7,algo-1]<stdout>:current_host=algo-1
[1,mpirank:7,algo-1]<stdout>:Opening process: ['python', './train_dnn.py', '--batch_size', '1024', '--epochs', '10', '--model_dir', '/opt/ml/model', '--num_of_data_workers', '0', '--steps_per_epoch', '500', '--tf_data_mode', 'local']
[1,mpirank:0,algo-1]<stdout>:env.is_hetero=False
[1,mpirank:0,algo-1]<stdout>:current_host=algo-1
[1,mpirank:0,algo-1]<stdout>:Opening process: ['python', './train_dnn.py', '--batch_size', '1024', '--epochs', '10', '--model_dir', '/opt/ml/model', '--num_of_data_workers', '0', '--steps_per_epoch', '500', '--tf_data_mode', 'local']
[1,mpirank:6,algo-1]<stdout>:env.is_hetero=False
[1,mpirank:6,algo-1]<stdout>:current_host=algo-1
[1,mpirank:6,algo-1]<stdout>:Opening process: ['python', './train_dnn.py', '--batch_size', '1024', '--epochs', '10', '--model_dir', '/opt/ml/model', '--num_of_data_workers', '0', '--steps_per_epoch', '500', '--tf_data_mode', 'local']
[1,mpirank:3,algo-1]<stdout>:env.is_hetero=False
[1,mpirank:3,algo-1]<stdout>:current_host=algo-1
[1,mpirank:3,algo-1]<stdout>:Opening process: ['python', './train_dnn.py', '--batch_size', '1024', '--epochs', '10', '--model_dir', '/opt/ml/model', '--num_of_data_workers', '0', '--steps_per_epoch', '500', '--tf_data_mode', 'local']
[1,mpirank:2,algo-1]<stdout>:env.is_hetero=False
[1,mpirank:2,algo-1]<stdout>:current_host=algo-1[1,mpirank:2,algo-1]<stdout>:
[1,mpirank:2,algo-1]<stdout>:Opening process: ['python', './train_dnn.py', '--batch_size', '1024', '--epochs', '10', '--model_dir', '/opt/ml/model', '--num_of_data_workers', '0', '--steps_per_epoch', '500', '--tf_data_mode', 'local']
[1,mpirank:1,algo-1]<stderr>:2022-09-24 11:37:25.276381: W tensorflow/core/profiler/internal/smprofiler_timeline.cc:460] Initializing the SageMaker Profiler.
[1,mpirank:2,algo-1]<stderr>:2022-09-24 11:37:25.276382: W tensorflow/core/profiler/internal/smprofiler_timeline.cc:460] Initializing the SageMaker Profiler.
[1,mpirank:4,algo-1]<stderr>:2022-09-24 11:37:25.276384: W tensorflow/core/profiler/internal/smprofiler_timeline.cc:460] Initializing the SageMaker Profiler.
[1,mpirank:1,algo-1]<stderr>:2022-09-24 11:37:25.276524: W tensorflow/core/profiler/internal/smprofiler_timeline.cc:105] SageMaker Profiler is not enabled. The timeline writer thread will not be started, future recorded events will be dropped.
[1,mpirank:2,algo-1]<stderr>:2022-09-24 11:37:25.276524: W tensorflow/core/profiler/internal/smprofiler_timeline.cc:105] SageMaker Profiler is not enabled. The timeline writer thread will not be started, future recorded events will be dropped.
[1,mpirank:4,algo-1]<stderr>:2022-09-24 11:37:25.276524: W tensorflow/core/profiler/internal/smprofiler_timeline.cc:105] SageMaker Profiler is not enabled. The timeline writer thread will not be started, future recorded events will be dropped.
[1,mpirank:0,algo-1]<stderr>:2022-09-24 11:37:25.290991: W tensorflow/core/profiler/internal/smprofiler_timeline.cc:460] Initializing the SageMaker Profiler.
[1,mpirank:7,algo-1]<stderr>:2022-09-24 11:37:25.290987: W tensorflow/core/profiler/internal/smprofiler_timeline.cc:460] Initializing the SageMaker Profiler.
[1,mpirank:3,algo-1]<stderr>:2022-09-24 11:37:25.290990: W tensorflow/core/profiler/internal/smprofiler_timeline.cc:460] Initializing the SageMaker Profiler.
[1,mpirank:5,algo-1]<stderr>:2022-09-24 11:37:25.290991: W tensorflow/core/profiler/internal/smprofiler_timeline.cc:460] Initializing the SageMaker Profiler.
[1,mpirank:6,algo-1]<stderr>:2022-09-24 11:37:25.290990: W tensorflow/core/profiler/internal/smprofiler_timeline.cc:460] Initializing the SageMaker Profiler.
[1,mpirank:0,algo-1]<stderr>:2022-09-24 11:37:25.291121: W tensorflow/core/profiler/internal/smprofiler_timeline.cc:105] SageMaker Profiler is not enabled. The timeline writer thread will not be started, future recorded events will be dropped.
[1,mpirank:7,algo-1]<stderr>:2022-09-24 11:37:25.291122: W tensorflow/core/profiler/internal/smprofiler_timeline.cc:105] SageMaker Profiler is not enabled. The timeline writer thread will not be started, future recorded events will be dropped.
[1,mpirank:3,algo-1]<stderr>:2022-09-24 11:37:25.291124: W tensorflow/core/profiler/internal/smprofiler_timeline.cc:105] SageMaker Profiler is not enabled. The timeline writer thread will not be started, future recorded events will be dropped.
[1,mpirank:5,algo-1]<stderr>:2022-09-24 11:37:25.291124: W tensorflow/core/profiler/internal/smprofiler_timeline.cc:105] SageMaker Profiler is not enabled. The timeline writer thread will not be started, future recorded events will be dropped.
[1,mpirank:6,algo-1]<stderr>:2022-09-24 11:37:25.291121: W tensorflow/core/profiler/internal/smprofiler_timeline.cc:105] SageMaker Profiler is not enabled. The timeline writer thread will not be started, future recorded events will be dropped.
[1,mpirank:4,algo-1]<stderr>:2022-09-24 11:37:25.310966: W tensorflow/core/profiler/internal/smprofiler_timeline.cc:460] Initializing the SageMaker Profiler.
[1,mpirank:2,algo-1]<stderr>:2022-09-24 11:37:25.310966: W tensorflow/core/profiler/internal/smprofiler_timeline.cc:460] Initializing the SageMaker Profiler.
[1,mpirank:1,algo-1]<stderr>:2022-09-24 11:37:25.310966: W tensorflow/core/profiler/internal/smprofiler_timeline.cc:460] Initializing the SageMaker Profiler.
[1,mpirank:0,algo-1]<stderr>:2022-09-24 11:37:25.325878: W tensorflow/core/profiler/internal/smprofiler_timeline.cc:460] Initializing the SageMaker Profiler.
[1,mpirank:7,algo-1]<stderr>:2022-09-24 11:37:25.325873: W tensorflow/core/profiler/internal/smprofiler_timeline.cc:460] Initializing the SageMaker Profiler.
[1,mpirank:3,algo-1]<stderr>:2022-09-24 11:37:25.325878: W tensorflow/core/profiler/internal/smprofiler_timeline.cc:460] Initializing the SageMaker Profiler.
[1,mpirank:6,algo-1]<stderr>:2022-09-24 11:37:25.326012: W tensorflow/core/profiler/internal/smprofiler_timeline.cc:460] Initializing the SageMaker Profiler.
[1,mpirank:5,algo-1]<stderr>:2022-09-24 11:37:25.326064: W tensorflow/core/profiler/internal/smprofiler_timeline.cc:460] Initializing the SageMaker Profiler.
[1,mpirank:6,algo-1]<stdout>:[PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU'), PhysicalDevice(name='/physical_device:GPU:1', device_type='GPU'), PhysicalDevice(name='/physical_device:GPU:2', device_type='GPU'), PhysicalDevice(name='/physical_device:GPU:3', device_type='GPU'), PhysicalDevice(name='/physical_device:GPU:4', device_type='GPU'), PhysicalDevice(name='/physical_device:GPU:5', device_type='GPU'), PhysicalDevice(name='/physical_device:GPU:6', device_type='GPU'), PhysicalDevice(name='/physical_device:GPU:7', device_type='GPU')]
[1,mpirank:0,algo-1]<stdout>:[PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU'), PhysicalDevice(name='/physical_device:GPU:1', device_type='GPU'), PhysicalDevice(name='/physical_device:GPU:2', device_type='GPU'), PhysicalDevice(name='/physical_device:GPU:3', device_type='GPU'), PhysicalDevice(name='/physical_device:GPU:4', device_type='GPU'), PhysicalDevice(name='/physical_device:GPU:5', device_type='GPU'), PhysicalDevice(name='/physical_device:GPU:6', device_type='GPU'), PhysicalDevice(name='/physical_device:GPU:7', device_type='GPU')]
[1,mpirank:0,algo-1]<stdout>:hvd.local_rank() 0
[1,mpirank:1,algo-1]<stdout>:[PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU'), PhysicalDevice(name='/physical_device:GPU:1', device_type='GPU'), PhysicalDevice(name='/physical_device:GPU:2', device_type='GPU'), PhysicalDevice(name='/physical_device:GPU:3', device_type='GPU'), PhysicalDevice(name='/physical_device:GPU:4', device_type='GPU'), PhysicalDevice(name='/physical_device:GPU:5', device_type='GPU'), PhysicalDevice(name='/physical_device:GPU:6', device_type='GPU'), PhysicalDevice(name='/physical_device:GPU:7', device_type='GPU')]
[1,mpirank:6,algo-1]<stdout>:hvd.local_rank() 6
[1,mpirank:1,algo-1]<stdout>:hvd.local_rank() 1
[1,mpirank:5,algo-1]<stdout>:[PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU'), PhysicalDevice(name='/physical_device:GPU:1', device_type='GPU'), PhysicalDevice(name='/physical_device:GPU:2', device_type='GPU'), PhysicalDevice(name='/physical_device:GPU:3', device_type='GPU'), PhysicalDevice(name='/physical_device:GPU:4', device_type='GPU'), PhysicalDevice(name='/physical_device:GPU:5', device_type='GPU'), PhysicalDevice(name='/physical_device:GPU:6', device_type='GPU'), PhysicalDevice(name='/physical_device:GPU:7', device_type='GPU')][1,mpirank:5,algo-1]<stdout>:
[1,mpirank:5,algo-1]<stdout>:hvd.local_rank() 5
[1,mpirank:2,algo-1]<stdout>:[PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU'), PhysicalDevice(name='/physical_device:GPU:1', device_type='GPU'), PhysicalDevice(name='/physical_device:GPU:2', device_type='GPU'), PhysicalDevice(name='/physical_device:GPU:3', device_type='GPU'), PhysicalDevice(name='/physical_device:GPU:4', device_type='GPU'), PhysicalDevice(name='/physical_device:GPU:5', device_type='GPU'), PhysicalDevice(name='/physical_device:GPU:6', device_type='GPU'), PhysicalDevice(name='/physical_device:GPU:7', device_type='GPU')]
[1,mpirank:3,algo-1]<stdout>:[PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU'), PhysicalDevice(name='/physical_device:GPU:1', device_type='GPU'), PhysicalDevice(name='/physical_device:GPU:2', device_type='GPU'), PhysicalDevice(name='/physical_device:GPU:3', device_type='GPU'), PhysicalDevice(name='/physical_device:GPU:4', device_type='GPU'), PhysicalDevice(name='/physical_device:GPU:5', device_type='GPU'), PhysicalDevice(name='/physical_device:GPU:6', device_type='GPU'), PhysicalDevice(name='/physical_device:GPU:7', device_type='GPU')]
[1,mpirank:4,algo-1]<stdout>:[PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU'), PhysicalDevice(name='/physical_device:GPU:1', device_type='GPU'), PhysicalDevice(name='/physical_device:GPU:2', device_type='GPU'), PhysicalDevice(name='/physical_device:GPU:3', device_type='GPU'), PhysicalDevice(name='/physical_device:GPU:4', device_type='GPU'), PhysicalDevice(name='/physical_device:GPU:5', device_type='GPU'), PhysicalDevice(name='/physical_device:GPU:6', device_type='GPU'), PhysicalDevice(name='/physical_device:GPU:7', device_type='GPU')]
[1,mpirank:2,algo-1]<stdout>:hvd.local_rank() 2
[1,mpirank:7,algo-1]<stdout>:[PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU'), PhysicalDevice(name='/physical_device:GPU:1', device_type='GPU'), PhysicalDevice(name='/physical_device:GPU:2', device_type='GPU'), PhysicalDevice(name='/physical_device:GPU:3', device_type='GPU'), PhysicalDevice(name='/physical_device:GPU:4', device_type='GPU'), PhysicalDevice(name='/physical_device:GPU:5', device_type='GPU'), PhysicalDevice(name='/physical_device:GPU:6', device_type='GPU'), PhysicalDevice(name='/physical_device:GPU:7', device_type='GPU')]
[1,mpirank:3,algo-1]<stdout>:hvd.local_rank() 3
[1,mpirank:4,algo-1]<stdout>:hvd.local_rank() 4
[1,mpirank:7,algo-1]<stdout>:hvd.local_rank() 7
[1,mpirank:3,algo-1]<stdout>:Running in local tf_data_mode.
[1,mpirank:6,algo-1]<stdout>:Running in local tf_data_mode.
[1,mpirank:5,algo-1]<stdout>:Running in local tf_data_mode.
[1,mpirank:0,algo-1]<stdout>:Running in local tf_data_mode.
[1,mpirank:7,algo-1]<stdout>:Running in local tf_data_mode.
[1,mpirank:2,algo-1]<stdout>:Running in local tf_data_mode.
[1,mpirank:1,algo-1]<stdout>:Running in local tf_data_mode.
[1,mpirank:4,algo-1]<stdout>:Running in local tf_data_mode.
[1,mpirank:1,algo-1]<stdout>:Epoch 1/10
[1,mpirank:4,algo-1]<stdout>:Epoch 1/10
[1,mpirank:2,algo-1]<stdout>:Epoch 1/10
[1,mpirank:3,algo-1]<stdout>:Epoch 1/10
[1,mpirank:5,algo-1]<stdout>:Epoch 1/10
[1,mpirank:7,algo-1]<stdout>:Epoch 1/10
[1,mpirank:0,algo-1]<stdout>:Epoch 1/10
[1,mpirank:6,algo-1]<stdout>:Epoch 1/10
[1,mpirank:5,algo-1]<stdout>:Extension horovod.torch has not been built: /usr/local/lib/python3.9/site-packages/horovod/torch/mpi_lib/_mpi_lib.cpython-39-x86_64-linux-gnu.so not found
[1,mpirank:5,algo-1]<stdout>:If this is not expected, reinstall Horovod with HOROVOD_WITH_PYTORCH=1 to debug the build error.
[1,mpirank:5,algo-1]<stdout>:Warning! MPI libs are missing, but python applications are still available.
[1,mpirank:0,algo-1]<stdout>:Extension horovod.torch has not been built: /usr/local/lib/python3.9/site-packages/horovod/torch/mpi_lib/_mpi_lib.cpython-39-x86_64-linux-gnu.so not found
[1,mpirank:0,algo-1]<stdout>:If this is not expected, reinstall Horovod with HOROVOD_WITH_PYTORCH=1 to debug the build error.
[1,mpirank:0,algo-1]<stdout>:Warning! MPI libs are missing, but python applications are still available.
[1,mpirank:7,algo-1]<stdout>:Extension horovod.torch has not been built: /usr/local/lib/python3.9/site-packages/horovod/torch/mpi_lib/_mpi_lib.cpython-39-x86_64-linux-gnu.so not found
[1,mpirank:7,algo-1]<stdout>:If this is not expected, reinstall Horovod with HOROVOD_WITH_PYTORCH=1 to debug the build error.
[1,mpirank:7,algo-1]<stdout>:Warning! MPI libs are missing, but python applications are still available.
[1,mpirank:3,algo-1]<stdout>:Extension horovod.torch has not been built: /usr/local/lib/python3.9/site-packages/horovod/torch/mpi_lib/_mpi_lib.cpython-39-x86_64-linux-gnu.so not found
[1,mpirank:3,algo-1]<stdout>:If this is not expected, reinstall Horovod with HOROVOD_WITH_PYTORCH=1 to debug the build error.
[1,mpirank:3,algo-1]<stdout>:Warning! MPI libs are missing, but python applications are still available.
[1,mpirank:1,algo-1]<stdout>:Extension horovod.torch has not been built: /usr/local/lib/python3.9/site-packages/horovod/torch/mpi_lib/_mpi_lib.cpython-39-x86_64-linux-gnu.so not found
[1,mpirank:1,algo-1]<stdout>:If this is not expected, reinstall Horovod with HOROVOD_WITH_PYTORCH=1 to debug the build error.
[1,mpirank:1,algo-1]<stdout>:Warning! MPI libs are missing, but python applications are still available.
[1,mpirank:2,algo-1]<stdout>:Extension horovod.torch has not been built: /usr/local/lib/python3.9/site-packages/horovod/torch/mpi_lib/_mpi_lib.cpython-39-x86_64-linux-gnu.so not found
[1,mpirank:2,algo-1]<stdout>:If this is not expected, reinstall Horovod with HOROVOD_WITH_PYTORCH=1 to debug the build error.
[1,mpirank:2,algo-1]<stdout>:Warning! MPI libs are missing, but python applications are still available.
[1,mpirank:4,algo-1]<stdout>:Extension horovod.torch has not been built: /usr/local/lib/python3.9/site-packages/horovod/torch/mpi_lib/_mpi_lib.cpython-39-x86_64-linux-gnu.so not found
[1,mpirank:4,algo-1]<stdout>:If this is not expected, reinstall Horovod with HOROVOD_WITH_PYTORCH=1 to debug the build error.
[1,mpirank:4,algo-1]<stdout>:Warning! MPI libs are missing, but python applications are still available.
[1,mpirank:6,algo-1]<stdout>:Extension horovod.torch has not been built: /usr/local/lib/python3.9/site-packages/horovod/torch/mpi_lib/_mpi_lib.cpython-39-x86_64-linux-gnu.so not found
[1,mpirank:6,algo-1]<stdout>:If this is not expected, reinstall Horovod with HOROVOD_WITH_PYTORCH=1 to debug the build error.
[1,mpirank:6,algo-1]<stdout>:Warning! MPI libs are missing, but python applications are still available.
[1,mpirank:1,algo-1]<stdout>:[2022-09-24 11:37:33.366 algo-1:177 INFO utils.py:27] RULE_JOB_STOP_SIGNAL_FILENAME: None
[1,mpirank:4,algo-1]<stdout>:[2022-09-24 11:37:33.366 algo-1:178 INFO utils.py:27] RULE_JOB_STOP_SIGNAL_FILENAME: None
[1,mpirank:5,algo-1]<stdout>:[2022-09-24 11:37:33.366 algo-1:179 INFO utils.py:27] RULE_JOB_STOP_SIGNAL_FILENAME: None
[1,mpirank:0,algo-1]<stdout>:[2022-09-24 11:37:33.366 algo-1:181 INFO utils.py:27] RULE_JOB_STOP_SIGNAL_FILENAME: None
[1,mpirank:3,algo-1]<stdout>:[2022-09-24 11:37:33.366 algo-1:183 INFO utils.py:27] RULE_JOB_STOP_SIGNAL_FILENAME: None
[1,mpirank:2,algo-1]<stdout>:[2022-09-24 11:37:33.366 algo-1:184 INFO utils.py:27] RULE_JOB_STOP_SIGNAL_FILENAME: None
[1,mpirank:6,algo-1]<stdout>:[2022-09-24 11:37:33.366 algo-1:182 INFO utils.py:27] RULE_JOB_STOP_SIGNAL_FILENAME: None
[1,mpirank:7,algo-1]<stdout>:[2022-09-24 11:37:33.366 algo-1:180 INFO utils.py:27] RULE_JOB_STOP_SIGNAL_FILENAME: None
[1,mpirank:1,algo-1]<stderr>:/usr/local/lib/python3.9/site-packages/smdebug-1.0.17b20220701-py3.9.egg/smdebug/profiler/system_metrics_reader.py:63: SyntaxWarning: "is not" with a literal. Did you mean "!="?
[1,mpirank:2,algo-1]<stderr>:/usr/local/lib/python3.9/site-packages/smdebug-1.0.17b20220701-py3.9.egg/smdebug/profiler/system_metrics_reader.py:63: SyntaxWarning: "is not" with a literal. Did you mean "!="?
[1,mpirank:4,algo-1]<stderr>:/usr/local/lib/python3.9/site-packages/smdebug-1.0.17b20220701-py3.9.egg/smdebug/profiler/system_metrics_reader.py:63: SyntaxWarning: "is not" with a literal. Did you mean "!="?
[1,mpirank:5,algo-1]<stderr>:/usr/local/lib/python3.9/site-packages/smdebug-1.0.17b20220701-py3.9.egg/smdebug/profiler/system_metrics_reader.py:63: SyntaxWarning: "is not" with a literal. Did you mean "!="?
[1,mpirank:6,algo-1]<stderr>:/usr/local/lib/python3.9/site-packages/smdebug-1.0.17b20220701-py3.9.egg/smdebug/profiler/system_metrics_reader.py:63: SyntaxWarning: "is not" with a literal. Did you mean "!="?
[1,mpirank:0,algo-1]<stderr>:/usr/local/lib/python3.9/site-packages/smdebug-1.0.17b20220701-py3.9.egg/smdebug/profiler/system_metrics_reader.py:63: SyntaxWarning: "is not" with a literal. Did you mean "!="?
[1,mpirank:3,algo-1]<stderr>:/usr/local/lib/python3.9/site-packages/smdebug-1.0.17b20220701-py3.9.egg/smdebug/profiler/system_metrics_reader.py:63: SyntaxWarning: "is not" with a literal. Did you mean "!="?
[1,mpirank:1,algo-1]<stderr>:/usr/local/lib/python3.9/site-packages/smdebug-1.0.17b20220701-py3.9.egg/smdebug/profiler/system_metrics_reader.py:63: SyntaxWarning: "is not" with a literal. Did you mean "!="?
[1,mpirank:2,algo-1]<stderr>:/usr/local/lib/python3.9/site-packages/smdebug-1.0.17b20220701-py3.9.egg/smdebug/profiler/system_metrics_reader.py:63: SyntaxWarning: "is not" with a literal. Did you mean "!="?
[1,mpirank:5,algo-1]<stderr>:/usr/local/lib/python3.9/site-packages/smdebug-1.0.17b20220701-py3.9.egg/smdebug/profiler/system_metrics_reader.py:63: SyntaxWarning: "is not" with a literal. Did you mean "!="?
[1,mpirank:4,algo-1]<stderr>:/usr/local/lib/python3.9/site-packages/smdebug-1.0.17b20220701-py3.9.egg/smdebug/profiler/system_metrics_reader.py:63: SyntaxWarning: "is not" with a literal. Did you mean "!="?
[1,mpirank:6,algo-1]<stderr>:/usr/local/lib/python3.9/site-packages/smdebug-1.0.17b20220701-py3.9.egg/smdebug/profiler/system_metrics_reader.py:63: SyntaxWarning: "is not" with a literal. Did you mean "!="?
[1,mpirank:7,algo-1]<stderr>:/usr/local/lib/python3.9/site-packages/smdebug-1.0.17b20220701-py3.9.egg/smdebug/profiler/system_metrics_reader.py:63: SyntaxWarning: "is not" with a literal. Did you mean "!="?
[1,mpirank:0,algo-1]<stderr>:/usr/local/lib/python3.9/site-packages/smdebug-1.0.17b20220701-py3.9.egg/smdebug/profiler/system_metrics_reader.py:63: SyntaxWarning: "is not" with a literal. Did you mean "!="?
[1,mpirank:3,algo-1]<stderr>:/usr/local/lib/python3.9/site-packages/smdebug-1.0.17b20220701-py3.9.egg/smdebug/profiler/system_metrics_reader.py:63: SyntaxWarning: "is not" with a literal. Did you mean "!="?
[1,mpirank:7,algo-1]<stderr>:/usr/local/lib/python3.9/site-packages/smdebug-1.0.17b20220701-py3.9.egg/smdebug/profiler/system_metrics_reader.py:63: SyntaxWarning: "is not" with a literal. Did you mean "!="?
[1,mpirank:1,algo-1]<stdout>:[2022-09-24 11:37:33.581 algo-1:177 INFO profiler_config_parser.py:111] Unable to find config at /opt/ml/input/config/profilerconfig.json. Profiler is disabled.
[1,mpirank:2,algo-1]<stdout>:[2022-09-24 11:37:33.581 algo-1:184 INFO profiler_config_parser.py:111] Unable to find config at /opt/ml/input/config/profilerconfig.json. Profiler is disabled.
[1,mpirank:0,algo-1]<stdout>:[2022-09-24 11:37:33.582 algo-1:181 INFO profiler_config_parser.py:111] Unable to find config at /opt/ml/input/config/profilerconfig.json. Profiler is disabled.
[1,mpirank:5,algo-1]<stdout>:[2022-09-24 11:37:33.582 algo-1:179 INFO profiler_config_parser.py:111] Unable to find config at /opt/ml/input/config/profilerconfig.json. Profiler is disabled.
[1,mpirank:7,algo-1]<stdout>:[2022-09-24 11:37:33.582 algo-1:180 INFO profiler_config_parser.py:111] Unable to find config at /opt/ml/input/config/profilerconfig.json. Profiler is disabled.
[1,mpirank:6,algo-1]<stdout>:[2022-09-24 11:37:33.582 algo-1:182 INFO profiler_config_parser.py:111] Unable to find config at /opt/ml/input/config/profilerconfig.json. Profiler is disabled.
[1,mpirank:3,algo-1]<stdout>:[2022-09-24 11:37:33.582 algo-1:183 INFO profiler_config_parser.py:111] Unable to find config at /opt/ml/input/config/profilerconfig.json. Profiler is disabled.
[1,mpirank:4,algo-1]<stdout>:[2022-09-24 11:37:33.582 algo-1:178 INFO profiler_config_parser.py:111] Unable to find config at /opt/ml/input/config/profilerconfig.json. Profiler is disabled.
[1,mpirank:2,algo-1]<stdout>:[2022-09-24 11:37:33.639 algo-1:184 INFO json_config.py:91] Creating hook from json_config at /opt/ml/input/config/debughookconfig.json.
[1,mpirank:1,algo-1]<stdout>:[2022-09-24 11:37:33.639 algo-1:177 INFO json_config.py:91] Creating hook from json_config at /opt/ml/input/config/debughookconfig.json.
[1,mpirank:4,algo-1]<stdout>:[2022-09-24 11:37:33.639 algo-1:178 INFO json_config.py:91] Creating hook from json_config at /opt/ml/input/config/debughookconfig.json.
[1,mpirank:3,algo-1]<stdout>:[2022-09-24 11:37:33.639 algo-1:183 INFO json_config.py:91] Creating hook from json_config at /opt/ml/input/config/debughookconfig.json.
[1,mpirank:7,algo-1]<stdout>:[2022-09-24 11:37:33.639 algo-1:180 INFO json_config.py:91] Creating hook from json_config at /opt/ml/input/config/debughookconfig.json.
[1,mpirank:6,algo-1]<stdout>:[2022-09-24 11:37:33.639 algo-1:182 INFO json_config.py:91] Creating hook from json_config at /opt/ml/input/config/debughookconfig.json.
[1,mpirank:0,algo-1]<stdout>:[2022-09-24 11:37:33.639 algo-1:181 INFO json_config.py:91] Creating hook from json_config at /opt/ml/input/config/debughookconfig.json.
[1,mpirank:5,algo-1]<stdout>:[2022-09-24 11:37:33.639 algo-1:179 INFO json_config.py:91] Creating hook from json_config at /opt/ml/input/config/debughookconfig.json.
[1,mpirank:1,algo-1]<stdout>:[2022-09-24 11:37:33.640 algo-1:177 INFO hook.py:201] tensorboard_dir has not been set for the hook. SMDebug will not be exporting tensorboard summaries.
[1,mpirank:4,algo-1]<stdout>:[2022-09-24 11:37:33.640 algo-1:178 INFO hook.py:201] tensorboard_dir has not been set for the hook. SMDebug will not be exporting tensorboard summaries.
[1,mpirank:2,algo-1]<stdout>:[2022-09-24 11:37:33.640 algo-1:184 INFO hook.py:201] tensorboard_dir has not been set for the hook. SMDebug will not be exporting tensorboard summaries.
[1,mpirank:3,algo-1]<stdout>:[2022-09-24 11:37:33.640 algo-1:183 INFO hook.py:201] tensorboard_dir has not been set for the hook. SMDebug will not be exporting tensorboard summaries.
[1,mpirank:7,algo-1]<stdout>:[2022-09-24 11:37:33.640 algo-1:180 INFO hook.py:201] tensorboard_dir has not been set for the hook. SMDebug will not be exporting tensorboard summaries.
[1,mpirank:6,algo-1]<stdout>:[2022-09-24 11:37:33.640 algo-1:182 INFO hook.py:201] tensorboard_dir has not been set for the hook. SMDebug will not be exporting tensorboard summaries.
[1,mpirank:0,algo-1]<stdout>:[2022-09-24 11:37:33.640 algo-1:181 INFO hook.py:201] tensorboard_dir has not been set for the hook. SMDebug will not be exporting tensorboard summaries.
[1,mpirank:2,algo-1]<stdout>:[2022-09-24 11:37:33.640 algo-1:184 INFO hook.py:254] Saving to /opt/ml/output/tensors
[1,mpirank:1,algo-1]<stdout>:[2022-09-24 11:37:33.640 algo-1:177 INFO hook.py:254] Saving to /opt/ml/output/tensors
[1,mpirank:4,algo-1]<stdout>:[2022-09-24 11:37:33.640 algo-1:178 INFO hook.py:254] Saving to /opt/ml/output/tensors
[1,mpirank:2,algo-1]<stdout>:[2022-09-24 11:37:33.640 algo-1:184 INFO state_store.py:77] The checkpoint config file /opt/ml/input/config/checkpointconfig.json does not exist.
[1,mpirank:4,algo-1]<stdout>:[2022-09-24 11:37:33.640 algo-1:178 INFO state_store.py:77] The checkpoint config file /opt/ml/input/config/checkpointconfig.json does not exist.
[1,mpirank:1,algo-1]<stdout>:[2022-09-24 11:37:33.640 algo-1:177 INFO state_store.py:77] The checkpoint config file /opt/ml/input/config/checkpointconfig.json does not exist.
[1,mpirank:5,algo-1]<stdout>:[2022-09-24 11:37:33.640 algo-1:179 INFO hook.py:201] tensorboard_dir has not been set for the hook. SMDebug will not be exporting tensorboard summaries.
[1,mpirank:3,algo-1]<stdout>:[2022-09-24 11:37:33.640 algo-1:183 INFO hook.py:254] Saving to /opt/ml/output/tensors
[1,mpirank:3,algo-1]<stdout>:[2022-09-24 11:37:33.640 algo-1:183 INFO state_store.py:77] The checkpoint config file /opt/ml/input/config/checkpointconfig.json does not exist.
[1,mpirank:2,algo-1]<stdout>:[2022-09-24 11:37:33.640 algo-1:184 INFO hook.py:421] Monitoring the collections: losses, sm_metrics, metrics
[1,mpirank:7,algo-1]<stdout>:[2022-09-24 11:37:33.640 algo-1:180 INFO hook.py:254] Saving to /opt/ml/output/tensors
[1,mpirank:6,algo-1]<stdout>:[2022-09-24 11:37:33.640 algo-1:182 INFO hook.py:254] Saving to /opt/ml/output/tensors
[1,mpirank:1,algo-1]<stdout>:[2022-09-24 11:37:33.640 algo-1:177 INFO hook.py:421] Monitoring the collections: losses, metrics, sm_metrics
[1,mpirank:4,algo-1]<stdout>:[2022-09-24 11:37:33.640 algo-1:178 INFO hook.py:421] Monitoring the collections: losses, metrics, sm_metrics
[1,mpirank:0,algo-1]<stdout>:[2022-09-24 11:37:33.640 algo-1:181 INFO hook.py:254] Saving to /opt/ml/output/tensors
[1,mpirank:7,algo-1]<stdout>:[2022-09-24 11:37:33.640 algo-1:180 INFO state_store.py:77] The checkpoint config file /opt/ml/input/config/checkpointconfig.json does not exist.
[1,mpirank:6,algo-1]<stdout>:[2022-09-24 11:37:33.640 algo-1:182 INFO state_store.py:77] The checkpoint config file /opt/ml/input/config/checkpointconfig.json does not exist.
[1,mpirank:0,algo-1]<stdout>:[2022-09-24 11:37:33.641 algo-1:181 INFO state_store.py:77] The checkpoint config file /opt/ml/input/config/checkpointconfig.json does not exist.
[1,mpirank:3,algo-1]<stdout>:[2022-09-24 11:37:33.641 algo-1:183 INFO hook.py:421] Monitoring the collections: losses, sm_metrics, metrics
[1,mpirank:6,algo-1]<stdout>:[2022-09-24 11:37:33.641 algo-1:182 INFO hook.py:421] Monitoring the collections: sm_metrics, metrics, losses
[1,mpirank:7,algo-1]<stdout>:[2022-09-24 11:37:33.641 algo-1:180 INFO hook.py:421] Monitoring the collections: sm_metrics, losses, metrics
[1,mpirank:0,algo-1]<stdout>:[2022-09-24 11:37:33.641 algo-1:181 INFO hook.py:421] Monitoring the collections: sm_metrics, metrics, losses
[1,mpirank:5,algo-1]<stdout>:[2022-09-24 11:37:33.641 algo-1:179 INFO hook.py:254] Saving to /opt/ml/output/tensors
[1,mpirank:5,algo-1]<stdout>:[2022-09-24 11:37:33.641 algo-1:179 INFO state_store.py:77] The checkpoint config file /opt/ml/input/config/checkpointconfig.json does not exist.
[1,mpirank:5,algo-1]<stdout>:[2022-09-24 11:37:33.641 algo-1:179 INFO hook.py:421] Monitoring the collections: metrics, losses, sm_metrics
[1,mpirank:0,algo-1]<stdout>:NCCL version 2.10.3+cuda11.2
[1,mpirank:2,algo-1]<stderr>:WARNING:tensorflow:Callback method `on_train_batch_end` is slow compared to the batch time (batch time: 0.2246s vs `on_train_batch_end` time: 0.6465s). Check your callbacks.
[1,mpirank:2,algo-1]<stderr>:WARNING:tensorflow:Callback method `on_train_batch_end` is slow compared to the batch time (batch time: 0.2246s vs `on_train_batch_end` time: 0.6465s). Check your callbacks.
[1,mpirank:3,algo-1]<stderr>:WARNING:tensorflow:Callback method `on_train_batch_end` is slow compared to the batch time (batch time: 0.2247s vs `on_train_batch_end` time: 0.6464s). Check your callbacks.
[1,mpirank:3,algo-1]<stderr>:WARNING:tensorflow:Callback method `on_train_batch_end` is slow compared to the batch time (batch time: 0.2247s vs `on_train_batch_end` time: 0.6464s). Check your callbacks.
[1,mpirank:0,algo-1]<stderr>:WARNING:tensorflow:Callback method `on_train_batch_end` is slow compared to the batch time (batch time: 0.2237s vs `on_train_batch_end` time: 0.6464s). Check your callbacks.
[1,mpirank:0,algo-1]<stderr>:WARNING:tensorflow:Callback method `on_train_batch_end` is slow compared to the batch time (batch time: 0.2237s vs `on_train_batch_end` time: 0.6464s). Check your callbacks.
[1,mpirank:5,algo-1]<stderr>:WARNING:tensorflow:Callback method `on_train_batch_end` is slow compared to the batch time (batch time: 0.2247s vs `on_train_batch_end` time: 0.6464s). Check your callbacks.
[1,mpirank:5,algo-1]<stderr>:WARNING:tensorflow:Callback method `on_train_batch_end` is slow compared to the batch time (batch time: 0.2247s vs `on_train_batch_end` time: 0.6464s). Check your callbacks.
[1,mpirank:7,algo-1]<stderr>:WARNING:tensorflow:Callback method `on_train_batch_end` is slow compared to the batch time (batch time: 0.2241s vs `on_train_batch_end` time: 0.6464s). Check your callbacks.
[1,mpirank:6,algo-1]<stderr>:WARNING:tensorflow:Callback method `on_train_batch_end` is slow compared to the batch time (batch time: 0.2247s vs `on_train_batch_end` time: 0.6465s). Check your callbacks.
[1,mpirank:7,algo-1]<stderr>:WARNING:tensorflow:Callback method `on_train_batch_end` is slow compared to the batch time (batch time: 0.2241s vs `on_train_batch_end` time: 0.6464s). Check your callbacks.
[1,mpirank:6,algo-1]<stderr>:WARNING:tensorflow:Callback method `on_train_batch_end` is slow compared to the batch time (batch time: 0.2247s vs `on_train_batch_end` time: 0.6465s). Check your callbacks.
[1,mpirank:1,algo-1]<stderr>:WARNING:tensorflow:Callback method `on_train_batch_end` is slow compared to the batch time (batch time: 0.2255s vs `on_train_batch_end` time: 0.6463s). Check your callbacks.
[1,mpirank:1,algo-1]<stderr>:WARNING:tensorflow:Callback method `on_train_batch_end` is slow compared to the batch time (batch time: 0.2255s vs `on_train_batch_end` time: 0.6463s). Check your callbacks.
[1,mpirank:4,algo-1]<stderr>:WARNING:tensorflow:Callback method `on_train_batch_end` is slow compared to the batch time (batch time: 0.2250s vs `on_train_batch_end` time: 0.6464s). Check your callbacks.
[1,mpirank:4,algo-1]<stderr>:WARNING:tensorflow:Callback method `on_train_batch_end` is slow compared to the batch time (batch time: 0.2250s vs `on_train_batch_end` time: 0.6464s). Check your callbacks.
[1,mpirank:7,algo-1]<stdout>:500/500 - 121s - loss: 2.4081 - lr: 0.0033 - 121s/epoch - 242ms/step
[1,mpirank:1,algo-1]<stdout>:500/500 - 121s - loss: 2.4081 - lr: 0.0033 - 121s/epoch - 242ms/step
[1,mpirank:2,algo-1]<stdout>:500/500 - 121s - loss: 2.4081 - lr: 0.0033 - 121s/epoch - 242ms/step
[1,mpirank:4,algo-1]<stdout>:500/500 - 121s - loss: 2.4081 - lr: 0.0033 - 121s/epoch - 242ms/step
[1,mpirank:6,algo-1]<stdout>:500/500 - 121s - loss: 2.4081 - lr: 0.0033 - 121s/epoch - 242ms/step
[1,mpirank:5,algo-1]<stdout>:500/500 - 121s - loss: 2.4081 - lr: 0.0033 - 121s/epoch - 242ms/step
[1,mpirank:1,algo-1]<stdout>:Epoch 2/10
[1,mpirank:5,algo-1]<stdout>:Epoch 2/10
[1,mpirank:7,algo-1]<stdout>:Epoch 2/10
[1,mpirank:6,algo-1]<stdout>:Epoch 2/10
[1,mpirank:2,algo-1]<stdout>:Epoch 2/10
[1,mpirank:4,algo-1]<stdout>:Epoch 2/10
[1,mpirank:3,algo-1]<stdout>:500/500 - 121s - loss: 2.4081 - lr: 0.0033 - 121s/epoch - 242ms/step
[1,mpirank:3,algo-1]<stdout>:Epoch 2/10
[1,mpirank:0,algo-1]<stdout>:500/500 - 122s - loss: 2.4081 - lr: 0.0033 - 122s/epoch - 245ms/step
[1,mpirank:0,algo-1]<stdout>:Epoch 2/10
[1,mpirank:1,algo-1]<stdout>:500/500 - 100s - loss: 2.3881 - lr: 0.0057 - 100s/epoch - 199ms/step
[1,mpirank:4,algo-1]<stdout>:500/500 - 100s - loss: 2.3881 - lr: 0.0057 - 100s/epoch - 199ms/step
[1,mpirank:7,algo-1]<stdout>:500/500 - 100s - loss: 2.3881 - lr: 0.0057 - 100s/epoch - 199ms/step
[1,mpirank:6,algo-1]<stdout>:500/500 - 100s - loss: 2.3881 - lr: 0.0057 - 100s/epoch - 199ms/step
[1,mpirank:5,algo-1]<stdout>:500/500 - 100s - loss: 2.3881 - lr: 0.0057 - 100s/epoch - 199ms/step
[1,mpirank:3,algo-1]<stdout>:500/500 - 100s - loss: 2.3881 - lr: 0.0057 - 100s/epoch - 199ms/step
[1,mpirank:2,algo-1]<stdout>:500/500 - 100s - loss: 2.3881 - lr: 0.0057 - 100s/epoch - 199ms/step
[1,mpirank:7,algo-1]<stdout>:Epoch 3/10
[1,mpirank:5,algo-1]<stdout>:Epoch 3/10
[1,mpirank:2,algo-1]<stdout>:Epoch 3/10
[1,mpirank:6,algo-1]<stdout>:Epoch 3/10
[1,mpirank:4,algo-1]<stdout>:Epoch 3/10
[1,mpirank:3,algo-1]<stdout>:Epoch 3/10
[1,mpirank:1,algo-1]<stdout>:Epoch 3/10
[1,mpirank:0,algo-1]<stdout>:500/500 - 99s - loss: 2.3881 - lr: 0.0057 - 99s/epoch - 199ms/step
[1,mpirank:0,algo-1]<stdout>:Epoch 3/10
[1,mpirank:6,algo-1]<stdout>:500/500 - 103s - loss: 2.3532 - lr: 0.0080 - 103s/epoch - 206ms/step
[1,mpirank:0,algo-1]<stdout>:
[1,mpirank:0,algo-1]<stdout>:Epoch 3: finished gradual learning rate warmup to 0.008.
[1,mpirank:7,algo-1]<stdout>:500/500 - 103s - loss: 2.3532 - lr: 0.0080 - 103s/epoch - 206ms/step
[1,mpirank:5,algo-1]<stdout>:500/500 - 103s - loss: 2.3532 - lr: 0.0080 - 103s/epoch - 206ms/step
[1,mpirank:2,algo-1]<stdout>:500/500 - 103s - loss: 2.3532 - lr: 0.0080 - 103s/epoch - 206ms/step
[1,mpirank:1,algo-1]<stdout>:500/500 - 103s - loss: 2.3532 - lr: 0.0080 - 103s/epoch - 206ms/step
[1,mpirank:3,algo-1]<stdout>:500/500 - 103s - loss: 2.3532 - lr: 0.0080 - 103s/epoch - 206ms/step
[1,mpirank:6,algo-1]<stdout>:Epoch 4/10
[1,mpirank:5,algo-1]<stdout>:Epoch 4/10
[1,mpirank:2,algo-1]<stdout>:Epoch 4/10
[1,mpirank:7,algo-1]<stdout>:Epoch 4/10
[1,mpirank:1,algo-1]<stdout>:Epoch 4/10
[1,mpirank:3,algo-1]<stdout>:Epoch 4/10
[1,mpirank:4,algo-1]<stdout>:500/500 - 103s - loss: 2.3532 - lr: 0.0080 - 103s/epoch - 206ms/step
[1,mpirank:4,algo-1]<stdout>:Epoch 4/10
[1,mpirank:0,algo-1]<stdout>:500/500 - 103s - loss: 2.3532 - lr: 0.0080 - 103s/epoch - 206ms/step
[1,mpirank:0,algo-1]<stdout>:Epoch 4/10
[1,mpirank:7,algo-1]<stdout>:500/500 - 103s - loss: 2.3199 - lr: 0.0080 - 103s/epoch - 206ms/step
[1,mpirank:6,algo-1]<stdout>:500/500 - 103s - loss: 2.3199 - lr: 0.0080 - 103s/epoch - 206ms/step
[1,mpirank:4,algo-1]<stdout>:500/500 - 103s - loss: 2.3199 - lr: 0.0080 - 103s/epoch - 206ms/step
[1,mpirank:2,algo-1]<stdout>:500/500 - 103s - loss: 2.3199 - lr: 0.0080 - 103s/epoch - 206ms/step
[1,mpirank:5,algo-1]<stdout>:500/500 - 103s - loss: 2.3199 - lr: 0.0080 - 103s/epoch - 206ms/step
[1,mpirank:1,algo-1]<stdout>:500/500 - 103s - loss: 2.3199 - lr: 0.0080 - 103s/epoch - 206ms/step
[1,mpirank:3,algo-1]<stdout>:500/500 - 103s - loss: 2.3199 - lr: 0.0080 - 103s/epoch - 206ms/step
[1,mpirank:6,algo-1]<stdout>:Epoch 5/10
[1,mpirank:7,algo-1]<stdout>:Epoch 5/10
[1,mpirank:4,algo-1]<stdout>:Epoch 5/10
[1,mpirank:1,algo-1]<stdout>:Epoch 5/10
[1,mpirank:2,algo-1]<stdout>:Epoch 5/10
[1,mpirank:3,algo-1]<stdout>:Epoch 5/10
[1,mpirank:5,algo-1]<stdout>:Epoch 5/10
[1,mpirank:0,algo-1]<stdout>:500/500 - 103s - loss: 2.3199 - lr: 0.0080 - 103s/epoch - 206ms/step
[1,mpirank:0,algo-1]<stdout>:Epoch 5/10
[1,mpirank:2,algo-1]<stdout>:500/500 - 100s - loss: 2.3071 - lr: 0.0080 - 100s/epoch - 200ms/step
[1,mpirank:6,algo-1]<stdout>:500/500 - 100s - loss: 2.3071 - lr: 0.0080 - 100s/epoch - 200ms/step
[1,mpirank:2,algo-1]<stdout>:Epoch 6/10
[1,mpirank:7,algo-1]<stdout>:500/500 - 100s - loss: 2.3071 - lr: 0.0080 - 100s/epoch - 200ms/step
[1,mpirank:5,algo-1]<stdout>:500/500 - 100s - loss: 2.3071 - lr: 0.0080 - 100s/epoch - 200ms/step
[1,mpirank:1,algo-1]<stdout>:500/500 - 100s - loss: 2.3071 - lr: 0.0080 - 100s/epoch - 200ms/step
[1,mpirank:6,algo-1]<stdout>:Epoch 6/10
[1,mpirank:3,algo-1]<stdout>:500/500 - 100s - loss: 2.3071 - lr: 0.0080 - 100s/epoch - 200ms/step
[1,mpirank:5,algo-1]<stdout>:Epoch 6/10
[1,mpirank:7,algo-1]<stdout>:Epoch 6/10
[1,mpirank:1,algo-1]<stdout>:Epoch 6/10
[1,mpirank:3,algo-1]<stdout>:Epoch 6/10
[1,mpirank:4,algo-1]<stdout>:500/500 - 100s - loss: 2.3071 - lr: 0.0080 - 100s/epoch - 200ms/step
[1,mpirank:4,algo-1]<stdout>:Epoch 6/10
[1,mpirank:0,algo-1]<stdout>:500/500 - 100s - loss: 2.3071 - lr: 0.0080 - 100s/epoch - 200ms/step
[1,mpirank:0,algo-1]<stdout>:Epoch 6/10
[1,mpirank:7,algo-1]<stdout>:500/500 - 94s - loss: 2.3043 - lr: 0.0080 - 94s/epoch - 188ms/step
[1,mpirank:4,algo-1]<stdout>:500/500 - 94s - loss: 2.3043 - lr: 0.0080 - 94s/epoch - 188ms/step
[1,mpirank:5,algo-1]<stdout>:500/500 - 94s - loss: 2.3043 - lr: 0.0080 - 94s/epoch - 188ms/step
[1,mpirank:2,algo-1]<stdout>:500/500 - 94s - loss: 2.3043 - lr: 0.0080 - 94s/epoch - 188ms/step
[1,mpirank:3,algo-1]<stdout>:500/500 - 94s - loss: 2.3043 - lr: 0.0080 - 94s/epoch - 188ms/step
[1,mpirank:4,algo-1]<stdout>:Epoch 7/10
[1,mpirank:5,algo-1]<stdout>:Epoch 7/10
[1,mpirank:3,algo-1]<stdout>:Epoch 7/10
[1,mpirank:7,algo-1]<stdout>:Epoch 7/10
[1,mpirank:1,algo-1]<stdout>:500/500 - 94s - loss: 2.3043 - lr: 0.0080 - 94s/epoch - 188ms/step
[1,mpirank:2,algo-1]<stdout>:Epoch 7/10
[1,mpirank:1,algo-1]<stdout>:Epoch 7/10
[1,mpirank:6,algo-1]<stdout>:500/500 - 94s - loss: 2.3043 - lr: 0.0080 - 94s/epoch - 188ms/step
[1,mpirank:6,algo-1]<stdout>:Epoch 7/10
[1,mpirank:0,algo-1]<stdout>:500/500 - 94s - loss: 2.3043 - lr: 0.0080 - 94s/epoch - 189ms/step
[1,mpirank:0,algo-1]<stdout>:Epoch 7/10
[1,mpirank:3,algo-1]<stdout>:500/500 - 97s - loss: 2.3031 - lr: 0.0080 - 97s/epoch - 194ms/step
[1,mpirank:5,algo-1]<stdout>:500/500 - 97s - loss: 2.3031 - lr: 0.0080 - 97s/epoch - 194ms/step
[1,mpirank:2,algo-1]<stdout>:500/500 - 97s - loss: 2.3031 - lr: 0.0080 - 97s/epoch - 194ms/step
[1,mpirank:1,algo-1]<stdout>:500/500 - 97s - loss: 2.3031 - lr: 0.0080 - 97s/epoch - 194ms/step
[1,mpirank:3,algo-1]<stdout>:Epoch 8/10
[1,mpirank:5,algo-1]<stdout>:Epoch 8/10
[1,mpirank:2,algo-1]<stdout>:Epoch 8/10
[1,mpirank:6,algo-1]<stdout>:500/500 - 97s - loss: 2.3031 - lr: 0.0080 - 97s/epoch - 194ms/step
[1,mpirank:7,algo-1]<stdout>:500/500 - 97s - loss: 2.3031 - lr: 0.0080 - 97s/epoch - 194ms/step
[1,mpirank:6,algo-1]<stdout>:Epoch 8/10
[1,mpirank:1,algo-1]<stdout>:Epoch 8/10
[1,mpirank:7,algo-1]<stdout>:Epoch 8/10
[1,mpirank:4,algo-1]<stdout>:500/500 - 97s - loss: 2.3031 - lr: 0.0080 - 97s/epoch - 194ms/step
[1,mpirank:4,algo-1]<stdout>:Epoch 8/10
[1,mpirank:0,algo-1]<stdout>:500/500 - 97s - loss: 2.3031 - lr: 0.0080 - 97s/epoch - 194ms/step
[1,mpirank:0,algo-1]<stdout>:Epoch 8/10
[1,mpirank:3,algo-1]<stdout>:500/500 - 96s - loss: 2.3027 - lr: 0.0080 - 96s/epoch - 192ms/step
[1,mpirank:5,algo-1]<stdout>:500/500 - 96s - loss: 2.3027 - lr: 0.0080 - 96s/epoch - 192ms/step
[1,mpirank:4,algo-1]<stdout>:500/500 - 96s - loss: 2.3027 - lr: 0.0080 - 96s/epoch - 192ms/step
[1,mpirank:7,algo-1]<stdout>:500/500 - 96s - loss: 2.3027 - lr: 0.0080 - 96s/epoch - 192ms/step
[1,mpirank:2,algo-1]<stdout>:500/500 - 96s - loss: 2.3027 - lr: 0.0080 - 96s/epoch - 192ms/step
[1,mpirank:6,algo-1]<stdout>:500/500 - 96s - loss: 2.3027 - lr: 0.0080 - 96s/epoch - 192ms/step
[1,mpirank:5,algo-1]<stdout>:Epoch 9/10
[1,mpirank:4,algo-1]<stdout>:Epoch 9/10
[1,mpirank:7,algo-1]<stdout>:Epoch 9/10
[1,mpirank:3,algo-1]<stdout>:Epoch 9/10
[1,mpirank:2,algo-1]<stdout>:Epoch 9/10
[1,mpirank:6,algo-1]<stdout>:Epoch 9/10
[1,mpirank:1,algo-1]<stdout>:500/500 - 96s - loss: 2.3027 - lr: 0.0080 - 96s/epoch - 192ms/step
[1,mpirank:1,algo-1]<stdout>:Epoch 9/10
[1,mpirank:0,algo-1]<stdout>:500/500 - 96s - loss: 2.3027 - lr: 0.0080 - 96s/epoch - 192ms/step
[1,mpirank:0,algo-1]<stdout>:Epoch 9/10
[1,mpirank:2,algo-1]<stdout>:500/500 - 105s - loss: 2.3021 - lr: 0.0080 - 105s/epoch - 210ms/step
[1,mpirank:3,algo-1]<stdout>:500/500 - 105s - loss: 2.3021 - lr: 0.0080 - 105s/epoch - 210ms/step
[1,mpirank:1,algo-1]<stdout>:500/500 - 105s - loss: 2.3021 - lr: 0.0080 - 105s/epoch - 210ms/step
[1,mpirank:5,algo-1]<stdout>:500/500 - 105s - loss: 2.3021 - lr: 0.0080 - 105s/epoch - 210ms/step
[1,mpirank:2,algo-1]<stdout>:Epoch 10/10
[1,mpirank:1,algo-1]<stdout>:Epoch 10/10
[1,mpirank:4,algo-1]<stdout>:500/500 - 105s - loss: 2.3021 - lr: 0.0080 - 105s/epoch - 210ms/step
[1,mpirank:6,algo-1]<stdout>:500/500 - 105s - loss: 2.3021 - lr: 0.0080 - 105s/epoch - 210ms/step
[1,mpirank:3,algo-1]<stdout>:Epoch 10/10
[1,mpirank:5,algo-1]<stdout>:Epoch 10/10
[1,mpirank:6,algo-1]<stdout>:Epoch 10/10
[1,mpirank:4,algo-1]<stdout>:Epoch 10/10
[1,mpirank:7,algo-1]<stdout>:500/500 - 105s - loss: 2.3021 - lr: 0.0080 - 105s/epoch - 210ms/step
[1,mpirank:7,algo-1]<stdout>:Epoch 10/10
[1,mpirank:0,algo-1]<stdout>:500/500 - 105s - loss: 2.3021 - lr: 0.0080 - 105s/epoch - 209ms/step
[1,mpirank:0,algo-1]<stdout>:Epoch 10/10
[1,mpirank:6,algo-1]<stdout>:500/500 - 97s - loss: 2.3013 - lr: 0.0080 - 97s/epoch - 194ms/step
[1,mpirank:7,algo-1]<stdout>:500/500 - 97s - loss: 2.3013 - lr: 0.0080 - 97s/epoch - 194ms/step
[1,mpirank:3,algo-1]<stdout>:500/500 - 97s - loss: 2.3013 - lr: 0.0080 - 97s/epoch - 194ms/step
[1,mpirank:2,algo-1]<stdout>:500/500 - 97s - loss: 2.3013 - lr: 0.0080 - 97s/epoch - 194ms/step
[1,mpirank:5,algo-1]<stdout>:500/500 - 97s - loss: 2.3013 - lr: 0.0080 - 97s/epoch - 194ms/step
[1,mpirank:1,algo-1]<stdout>:500/500 - 97s - loss: 2.3013 - lr: 0.0080 - 97s/epoch - 194ms/step
[1,mpirank:4,algo-1]<stdout>:500/500 - 97s - loss: 2.3013 - lr: 0.0080 - 97s/epoch - 194ms/step
[1,mpirank:0,algo-1]<stdout>:500/500 - 97s - loss: 2.3013 - lr: 0.0080 - 97s/epoch - 193ms/step
[1,mpirank:4,algo-1]<stdout>:Process train_dnn.py closed with returncode=0
[1,mpirank:6,algo-1]<stdout>:Process train_dnn.py closed with returncode=0
[1,mpirank:3,algo-1]<stdout>:Process train_dnn.py closed with returncode=0
[1,mpirank:1,algo-1]<stdout>:Process train_dnn.py closed with returncode=0
[1,mpirank:5,algo-1]<stdout>:Process train_dnn.py closed with returncode=0
[1,mpirank:7,algo-1]<stdout>:Process train_dnn.py closed with returncode=0
[1,mpirank:2,algo-1]<stdout>:Process train_dnn.py closed with returncode=0
[1,mpirank:0,algo-1]<stderr>:WARNING:absl:Found untraced functions such as _jit_compiled_convolution_op, _jit_compiled_convolution_op, _jit_compiled_convolution_op, _jit_compiled_convolution_op, _jit_compiled_convolution_op while saving (showing 5 of 53). These functions will not be directly callable after loading.
[1,mpirank:0,algo-1]<stderr>:INFO:tensorflow:Assets written to: /opt/ml/model/000000001/assets
[1,mpirank:0,algo-1]<stderr>:INFO:tensorflow:Assets written to: /opt/ml/model/000000001/assets
[1,mpirank:0,algo-1]<stdout>:Process train_dnn.py closed with returncode=0
2022-09-24 11:54:50,061 sagemaker-training-toolkit INFO Waiting for the process to finish and give a return code.
2022-09-24 11:54:50,061 sagemaker-training-toolkit INFO Done waiting for a return code. Received 0 from exiting process.
2022-09-24 11:54:50,062 sagemaker-training-toolkit INFO Reporting training SUCCESS
2022-09-24 11:55:05 Uploading - Uploading generated training model
2022-09-24 11:55:36 Completed - Training job completed
Training seconds: 1337
Billable seconds: 1337
Step 3: Analyzing the homogeneous training job throughput and resource usage
We’ll examine: CPU and GPU usage. Epoch time and step time
CPU and GPU usage analysis
In the screenshot below we observe that close to all the 96 vCPU of the instance is utilized. While GPU utilization is only ~45%. Clearly if we had more vCPUs we could increase GPU usage significantly to increase job throughput
Epoch time and step time analysis
For 2nd and 3rd epochs the below should print out: 105s/epoch - 209ms/step.
[10]:
%%capture homogeneous_logs
estimator.sagemaker_session.logs_for_job(estimator.latest_training_job.name)
[12]:
print(f"Printing step time for epochs and steps for {estimator.latest_training_job.name}")
for line in homogeneous_logs.stdout.split("\n"):
if "mpirank:0" in line and "/epoch" in line:
print(line)
Printing step time for epochs and steps for homogeneous-20220923T231801Z
[1,mpirank:0,algo-1]<stdout>:500/500 - 117s - loss: 2.4153 - lr: 0.0033 - 117s/epoch - 234ms/step
[1,mpirank:0,algo-1]<stdout>:500/500 - 92s - loss: 2.3755 - lr: 0.0057 - 92s/epoch - 184ms/step
[1,mpirank:0,algo-1]<stdout>:500/500 - 92s - loss: 2.3472 - lr: 0.0080 - 92s/epoch - 184ms/step
[1,mpirank:0,algo-1]<stdout>:500/500 - 92s - loss: 2.3175 - lr: 0.0080 - 92s/epoch - 184ms/step
[1,mpirank:0,algo-1]<stdout>:500/500 - 92s - loss: 2.3066 - lr: 0.0080 - 92s/epoch - 183ms/step
[1,mpirank:0,algo-1]<stdout>:500/500 - 90s - loss: 2.3043 - lr: 0.0080 - 90s/epoch - 181ms/step
[1,mpirank:0,algo-1]<stdout>:500/500 - 94s - loss: 2.3028 - lr: 0.0080 - 94s/epoch - 189ms/step
[1,mpirank:0,algo-1]<stdout>:500/500 - 92s - loss: 2.3024 - lr: 0.0080 - 92s/epoch - 184ms/step
[1,mpirank:0,algo-1]<stdout>:500/500 - 93s - loss: 2.3021 - lr: 0.0080 - 93s/epoch - 185ms/step
[1,mpirank:0,algo-1]<stdout>:500/500 - 89s - loss: 2.3018 - lr: 0.0080 - 89s/epoch - 177ms/step
D. Run a heterogeneous cluster training job
Step 1: Set up training environment
estimator as the instance_groups parameter that replaces the homogeneous parameters instance_type and instance_count. - In the distribution parameter for Horovod we added a new parameter instance_groups that is used to limit the MPI cluster to run in the dnn_group. The MPI cluster should include only the GPU nodes that run Horovod (which needs MPI). The data_group instances should not be part of the
MPI cluster, as they set up their on tf.data.service cluster.More on the two instance groups config we use: - data_group - two ml.c5.18xlarge instances, each with 72 vCPUs to handle data preprocessing. Reading data from S3, preprocessing it, and forwarding it to the dnn_group. - dnn_group - a single p4d.24xlarge instance, with 8 GPUs and 96 vCPUs to handle deep neural network optimization (forward backward passes). To fully utilize 96 vCPUs in the dnn_group, we’ll be starting data workers on all the instances in both groups, therefore we
have 240 vCPUs (96+72+72) in total available for preprocessing (minus vCPUs used for the neural network optimization process).
train_dnn.py - This is your training script for the neural network, you should edit it to match your own use case. Note that this script isn’t aware of the Heterogeneous cluster set up, except when it initializes the tf.data dataset calling this line: ds = ds.apply(tf.data.experimental.service.distribute(...).train_data.py include functions to start/stop tf.service.data process like a dispatcher and WorkerServer. launcher.py has several responsibilities: - A single entry point script for all instances in all instance groups (SageMaker will start the same script on all instances). - Identifies which instance group the node belong to, and start the relevant script accordingly (train_dnn.py or train_data.py or sometimes both). - Takes measures to ensure that tf.data.service processes
shutdown when training completes, as the training job completes only when all instances exit. - Allow to start more than one process (for example, on the dnn_group instances we’ll run both the train_dnn.py and a tf.data.service worker to utilize the instance CPUs).[14]:
import datetime
from sagemaker.tensorflow import TensorFlow
from sagemaker.instance_group import InstanceGroup
from sagemaker.inputs import TrainingInput
import os
hyperparameters = {
"epochs": 10,
"steps_per_epoch": 500,
"batch_size": 1024,
"tf_data_mode": "service", # Using tf.data.service for this Heterogeneous cluster job
"num_of_data_workers": 1, # One tf.data.service worker per node
}
# Group for CPU instances to run tf.data.service dispatcher/workers processes.
data_group = InstanceGroup("data_group", "ml.c5.18xlarge", 2)
# Group for deep neural network (dnn) with accleartors (e.g., GPU, FPGA, etc.)
dnn_group = InstanceGroup("dnn_group", "ml.p4d.24xlarge", 1)
estimator2 = TensorFlow(
entry_point="launcher.py",
source_dir="code",
framework_version="2.9.1",
py_version="py39",
role=role,
volume_size=10,
max_run=1800, # 30 minutes
disable_profiler=True,
# instance_type='ml.p4d.24xlarge',
# instance_count=1,
instance_groups=[data_group, dnn_group],
hyperparameters=hyperparameters,
distribution={
"mpi": {
"enabled": True,
"processes_per_host": 8, # p4d.24xlarge has 8 GPUs per host
"custom_mpi_options": "--NCCL_DEBUG WARN",
},
"instance_groups": [dnn_group], # Apply distribution strategy to the dnn_group only
},
)
Step 2: Submit the training job
Note1: For the logs, click on View logs from the Training Jobs node in Amazon SageMaker Console. Note2: Ignore the 0 billable seconds shown below. See actual billable seconds in the AWS web console > SageMaker > Training Jobs > this job.
[16]:
from start_job_utils import fit_with_retries
fit_with_retries(5, estimator2,
job_name="heterogeneous-" + datetime.datetime.utcnow().strftime("%Y%m%dT%H%M%SZ"),
)
2022-09-23 23:52:33 Starting - Starting the training job......
2022-09-23 23:53:17 Starting - Preparing the instances for training........................
2022-09-23 23:57:33 Downloading - Downloading input data...
2022-09-23 23:57:48 Training - Downloading the training image...........................
2022-09-24 00:02:25 Training - Training image download completed. Training in progress....................................................
2022-09-24 00:11:23 Uploading - Uploading generated training model...
2022-09-24 00:11:59 Completed - Training job completed
Step 3: Analyze the heterogeneous cluster training job’s throughput and resource usage
We’ll examine: CPU and GPU usage. Epoch time and step time.
CPU and GPU usage analysis
In the screenshot below we observe that GPU usage has increase to 74% (compared to ~45% in the homogeneous training run) which is what we were aiming for. The CPU usage on all 3 instances are close to 80% CPU usage.
Epoch time and step time analysis
For 2nd epoch onwards you should see this print out in the logs of the dnn_group instance (p4d.24xlarge): 43s/epoch - 86ms/step. Note that the instances are named: Algo1, Algo2, Algo3 randomly on each execution, so you’ll need to open all instances logs to find the dnn_group instance.
The table below summarizes both jobs. We can see that: - The Heterogeneous job is 2.2x faster to train (86ms/step) than the homogeneous job (192ms/step). - The Heterogeneous job is 45% cheaper to train than the homogeneous job. This is despite the heterogeneous costs more per hour ($45/hour vs $37/hour), due to the two extra c5.18xlarge instances included in the heterogeneous job ($45 = $37.7 + 2 * $3.67 The cost-to-train formula we used: change in hourly price ($45/$37.7) times
reduction-in-time-to-train (86ms/192ms) = 45% = ($45/$37.7) * (86ms/192ms).
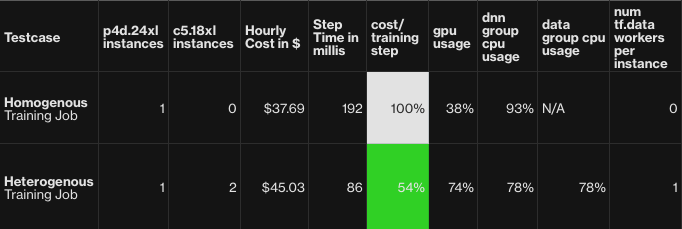
In this notebook, we demonstrated how to leverage Heterogeneous cluster feature of SageMaker Training, with TensorFlow to achieve better price performance and increase training speed. To get started you can copy this example project and change train_dnn.py to match your workload. To run the job, you could use this notebook, or the start_job.py.